Using text embeddings to analyze workout data from Strava
I’ve been using Strava, a popular platform for tracking workouts and fitness activities, to collect data on my running workouts. The Strava API provides access to this data, which I can then use to train machine learning models and gain insights into my workouts.
The big challenge is to convert this into a useful format. I converted them to the elegant Vowpal Wabbit format, and trained a model predict goal-dependent workouts using upside down reinforcement learning. It somewhat worked, but I kept getting lost in feature engineering, such as heart rate zones and training types.
During my holidays I realized that large language models might be powerful enough to directly work with structured data I get from the API. That way I could directly work with the raw data, and use language to drive my modelling.
For a simple proof of principle, I created JSON documents for workouts like this:
{
"title": "Trailschoenen proberen",
"sport": "TrailRun",
"moving_minutes": 44,
"distance_km": 8.0,
"heartrate_bpm": 134.2,
"max_heartrate_bpm": 146.0,
"speed_meters_per_second": 3.016,
"max_speed_meters_per_second": 4.456,
"total_elevation_gain_meters": 37.0,
"cadence_bpm": 82.6
}
These can be embedded into a high-dimensional vector with a text embedding model:
ollama.embeddings(model="nomic-embed-text", prompt=json.dumps(workout))
Hopefully these embeddings retain information about the workout that was described. To test that, we create embed some workout-related concepts, such as sport type, intensity and environment, and see if those embeddings are similar to the correct workouts:
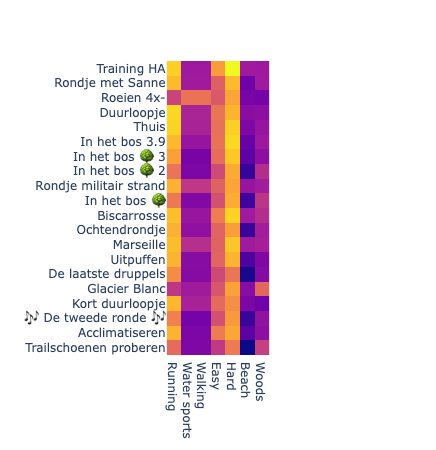
Above is a cosine similarity matrix for the text embeddings. To interpret the results, one needs to know the workouts of course. I can tell that concepts are related to the workouts, but sometimes superficially, like one would get with a bag-of-word representation.
I expect that this approach will get more viable. That means that language would be a generic representation for data, and diverse models and programs can interact with the same data. But right now it is too early for production use. Maybe next week’s models will be better…